Azure Event Hubs and Amazon Kinesis are two competing cloud services that serve the same purpose – reliably collect and process massive amounts of data with low latency and at low cost. Although both services provide similar functionality, there are significant differences to be aware of when architecting a solution. This article compares various aspects of Azure Event Hubs and Amazon Kinesis and is intended to assist in the software architecture decision-making process.
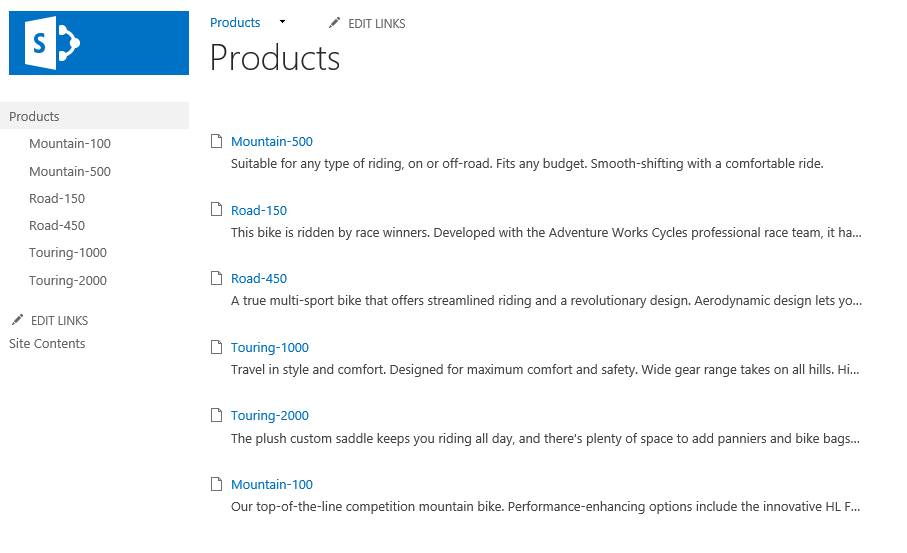
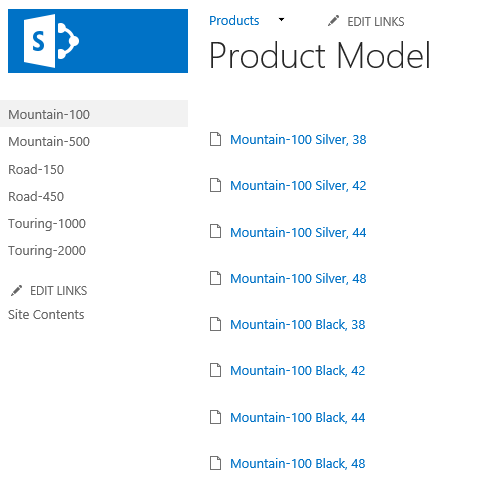
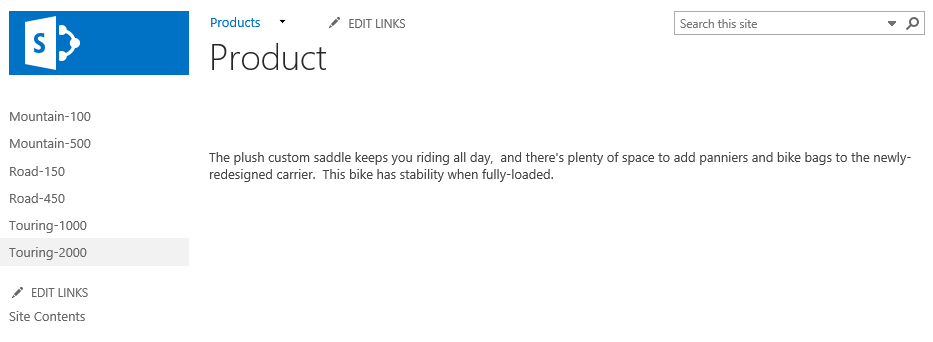
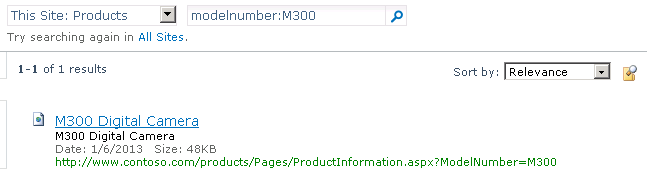
Key concepts
Amazon Kinesis streams use shards as the base throughput units. Each shard provides a capacity of 1MB/sec data input and 2MB/sec data output, supports up to 1,000 PUT records and up to 5 read transactions per second. The default shard limit depends on a region and is either 25 or 50 shards per region but you can request an increase. There is no upper limit to the number of shards in a stream or account.
Azure Event Hubs stream throughput capacity is controlled by throughput units. One throughput unit includes up to 1MB/sec ingress, up to 2MB/sec egress, and supports 1,000 events per second. Event Hubs also introduce a concept of partitions – a data organization mechanism designed to support multiple concurrent readers. A single partition has a maximum scale of one throughput unit. There’s a default limit of 20 throughput units per Azure account and 32 partitions per Event Hub but both limits can be increased by request.
Data input
Amazon Kinesis API uses HTTPS protocol for all operations. Every put request must be signed using an access key. You can control the level of access to Amazon Kinesis resources using AWS Identity and Access Management (IAM). IAM policies that only allow write operations to specific streams can be used to add data records. Data producers can also use the Amazon Kinesis Producer Library (KPL) to simplify producer application development. The maximum size of a data blob (the data payload before Base64-encoding) is 1MB.
Azure Event Hubs support HTTPS and AMQP 1.0 protocols for event publishing. Event publishers use Shared Access Signature (SAS) tokens for authentication. SAS tokens for event publishers can be created with send-only privileges on a specific Event Hub. .NET developers can take advantage of the EventHubClient for publishing events to Event Hubs and Apache Qpid project can be used for sending messages over AMQP from a variety of platforms and languages. You can send up to 256KB of event data in a single request. Publisher policies is a distinctive feature of Azure Event Hubs that is designed to facilitate large numbers of independent event producers.
Data processing
Amazon Kinesis consumer applications can read data from streams using either Amazon Kinesis API or Amazon Kinesis Client Library (KCL). Amazon Kinesis Client Library (KCL) makes it easier to build robust applications that read and process stream data by handling complexities typically associated with distributed stream processing. Amazon Kinesis Connector Library helps you integrate Amazon Kinesis with other AWS services and third-party tools and provides connectors to Amazon DynamoDB, Amazon Redshift, Amazon S3, and Elasticsearch. Amazon Kinesis Storm Spout library helps Java developers integrate Amazon Kinesis with Apache Storm.
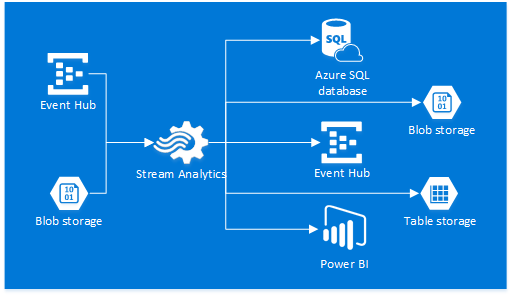
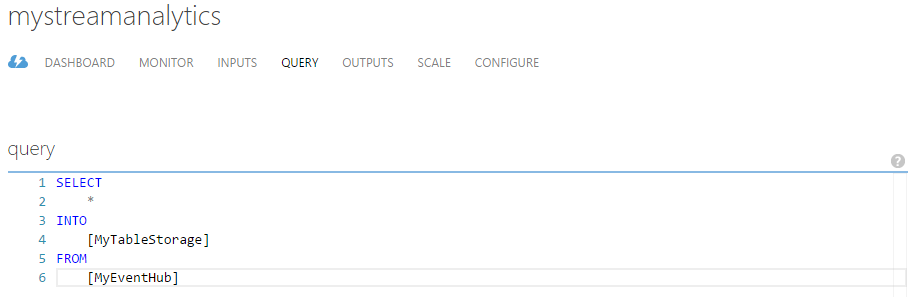
Azure Event Hubs consumers connect via the AMQP 1.0 session, in which events are delivered as they become available. Consumer groups allow multiple consuming applications to read the same stream independently at their own pace. You can create up 20 consumer groups per Event Hub. The EventProcessorHost class can significantly simplify distributed partition processing for .NET clients. Azure Steam Analytics service provides out-of-the-box integration with Event Hubs and can be used to process ingested events in real-time. Stream Analytics supports Azure SQL database, Blob storage, Event Hub, Table storage, and Power BI output sink options.
Monitoring
Amazon Kinesis integrates with Amazon CloudWatch service which is a reliable, scalable, and flexible monitoring solution that enables you to collect, view, and analyze CloudWatch metrics for your Amazon Kinesis streams.
Azure Event Hubs don’t provide a built-in monitoring and notification mechanism beyond the basic metrics available on the Azure management portal at the time of writing.
Capacity management
Amazon Kinesis stream throughput is limited by the number of shards within the stream. A resharding operation must be performed in order to increase (split) or decrease (merge) the number of shards. Stream data records are accessible for a maximum of 24 hours from the time they are added to the stream.
Azure Event Hubs ingress is throttled and egress is limited to the amount of capacity provided by the number of throughput units assigned to the stream. Throughput units are provisioned on a best effort basis and may not always be available for immediate purchase. The default Event Hubs message retention period is 24 hours but the Event Hubs Standard tier supports a maximum retention period of 7 days.
Pricing
Amazon Kinesis uses simple pay as you go pricing and is based on two dimensions: Shard Hour and PUT Payload Unit (25KB payload chunk). The pricing varies by region and is $0.015/hr per shard and $0.014 per 1,000,000 PUT payload units in the US East.
Azure Event Hubs use tiered pricing model and charge by the number of assigned throughput units and ingress events (units of data 64KB or less). The Event Hubs Basic tier costs $0.015/hr per throughput unit and $0.028 per million events while the Event Hubs Standard costs $0.03/hr per throughput unit and $0.028 per million events in the Central US region. Service Bus brokered connections (AMQP connections) are billed separately but the first 100 concurrent connections are free for every Basic Event Hubs namespace, and the first 1,000 concurrent connections per subscription are free for Standard Event Hubs.
Additional resources